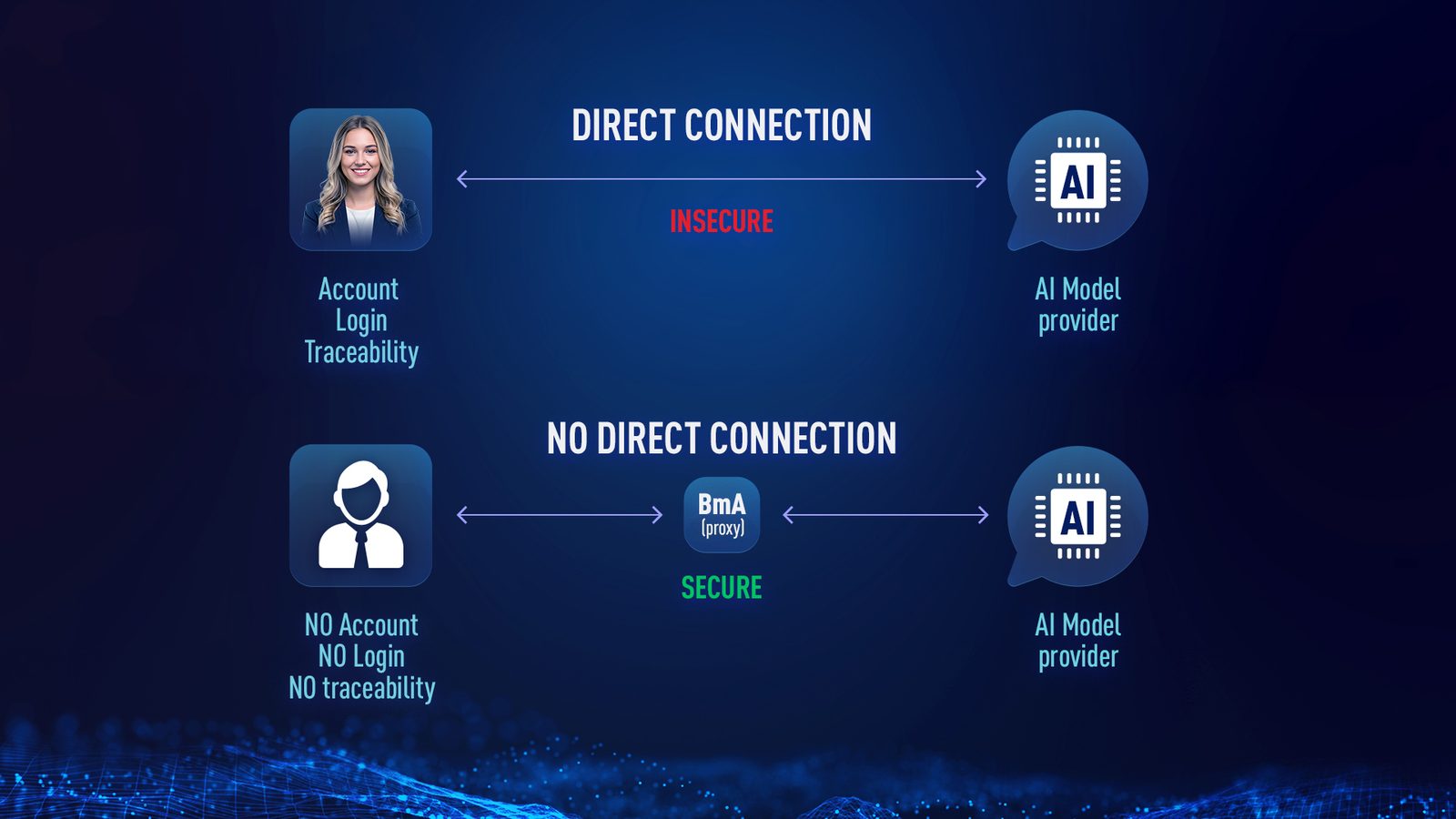
No accounts. No API keys. No direct line to the AI company.
Your researchers never sign up with OpenAI, Anthropic, or Google. They sign in to BioMed Advisor. We handle the model calls on their behalf, so the AI company never has a record that ties back to your team.
As far as the AI company can tell, every request comes from BioMed Advisor. Not from your researcher. Not from your institution. That separation is the first line of defense.
The right model for the question. No one provider sees the whole picture.
No single AI model is best at everything. BioMed Advisor routes each question to the model best suited for it: chemistry questions to one model, literature synthesis to another, hypothesis work to a third. You get better answers because the right model is doing the work.
The privacy benefit is structural. Because your queries are distributed across providers based on task, no single vendor accumulates enough of your activity to build a profile of your research over time.

Your questions get lost in the crowd.
We send thousands of biomedical questions to AI companies every day, from researchers all over the world, on completely unrelated topics. Your specific question about a binding affinity or a grant draft sits inside that stream, mixed in with everyone else's. Picking yours out of the traffic is not a problem anyone is set up to solve.
Your unpublished research stays unpublished.
When you upload a draft proposal, an unpublished paper, or a sensitive PDF, it goes through the Secure Document Chat. The model reads it for the length of the question, then it is gone. The document is never saved to an AI company's disk.
Your draft proposals and unpublished work never become training data, because nothing is ever stored.
Your data stays in your region, governed by your local law.
BioMed Advisor can deploy as a private cloud in your region of choice: the United States, the European Union, Canada, the United Kingdom, or selected regions in Asia. For institutions that require it, on-premises deployment in your own data center is also available. Your data stays there. Your queries originate there. The law that governs your institution governs the AI you use.
For US-based institutions, that means a US deployment. For institutions outside the US that need to avoid the US CLOUD Act or US discovery, that means a deployment in their own jurisdiction. Additional regions are available on request.